Por Joaquín Diaz Velez.
Problema de negocio: “caja negra”. Conozco dos cosas con el nombre “caja negra”: la que, tal vez, la mayoría conoce (que en realidad es de color naranja y va en los aviones), y el término que se identifica a una solución de software cuando uno prefiere no saber qué pasa ahí adentro o lo ignora completamente y sólo trabaja con sus resultados. La caja negra del software es la que nos convoca en este instante
El software debe empezar a transparentarse, y la caja negra a aclararse. Una organización que depende parcial o totalmente de una producto digital no puede darse el lujo de ignorar lo que está pasando dentro de la caja negra. Conocer lo que está pasando dentro de un software u observar qué está ocurriendo dentro de la aplicación puede convertirse en una ventaja muy grande dentro del mercado. Observar cómo funciona internamente una aplicación nos permite obtener información rápida y precisa sobre algún inconveniente. Y la información, disponibilizada por los canales correctos, da a nuestros usuarios el poder para resolver sus inconvenientes.

Debemos recordar que nuestra terminal se está transformando digitalmente, y en escenarios de quiebre de servicios necesitamos obtener la información de primera mano. Las marchas y contramarchas son costosas cuando hay transportes, buques y personas que dependen del correcto funcionamiento de una aplicación.
Los inconvenientes de nuestros stakeholders o clientes nos llegan en forma de queja o reclamo (a veces, es el único recurso que tienen para tratar de solucionar algún problema). Y si la incidencia es de difícil reproducción, puede ocurrir que el usuario se convierta en el “principal sospechoso” del caso. Algunas de las causas más frecuentes:
- “Seguramente tenía poca conectividad”.
- “Nunca antes pasó, así que tal vez tiene un virus en su PC”.
- “En las pruebas nunca nos sucedió nada parecido”.
- “No hemos tocado nada para que deje de andar ese componente”.
- Alguna otra razón de su gusto.
Es momento de dejar de victimizar a nuestros clientes o usuarios buscando resolver sus problemas, y de pasar a tratarlos como los actores que posibilitan que nuestro negocio funcione. Por lo tanto, es momento de dar un gran paso adelante en la forma en que se construyen y piensan las soluciones o productos digitales para las terminales portuarias.
La forma en que se construye software ha cambiado radicalmente en los últimos 5 años. Es muy clara la evolución de ciertas prácticas, a la par que se complementan unas con otras. Los equipos de desarrollo se volvieron multidisciplinarios para abordar una solución de punta a punta. Los sistemas se empezaron a distribuir más, rompiendo con las clásicas arquitecturas monolíticas y virando hacia arquitecturas de microservicios o serverless. La infraestructura dejó de ser on-premise para ir a servicios Cloud, con aprovisionamiento bajo demanda de manera automática. Apareció la cultura DevOps y una manera diferentes de encarar los desafíos al llevar una aplicación a producción.
Toda esta nueva complejidad también trajo consigo cambios en cómo controlamos la salud de nuestros sistemas. No es lo mismo entender qué pasa con una sola gran aplicación, que con una aplicación que consta de 30 microservicios en donde cada uno puede escalar de manera independiente. Esto requiere trabajar en diferentes aspectos para controlar desde distintas aristas. Ya no monitoreamos más: ahora observamos. Apareció el concepto de “Observabilidad”.
Pero, ¿qué es la Observabilidad?
Podemos definirla como la forma de medir qué tan bueno es el estado de un sistema a partir de sus salidas externas. Un sistema es observable si el estado actual puede ser determinado en un período de tiempo finito sólo a través de sus salidas.
La infraestructura de IT consta de componentes de hardware y software que generan automáticamente registros de cada actividad en el sistema, y que incluyen las actividades de las aplicaciones, de las bases de datos, de los controles de seguridad, entre otros. La idea es utilizarlos y procesarlos para conocer el estado del sistema.
El concepto de Observabilidad se puede dividir en tres grandes temas: event logs, metrics y traces. Cada uno apunta a una necesidad diferente.
Elementos a observar
Un event log es un registro de un evento que sucedió en un sistema. Los registros de eventos suelen estar “timestampeados”, y contienen un mensaje que refiere a lo ocurrido con un grado de severidad. Usualmente éstos se almacenan en archivos o directamente se entregan a través de la salida por defecto de los procesos. En conjunto, proporcionan un registro completo y preciso de eventos discretos, incluídos metadatos adicionales sobre el estado del sistema cuando ocurrió el evento. Estos solían escribirse en texto sin formato, pero ahora se tiende a ir por logs estructurados para tener la capacidad de procesarlos posteriormente con facilidad.
Por otro lado, una metric es una representación numérica de datos que se midieron durante un período de tiempo. A diferencia de un event log, que registra un evento específico, una métrica es un valor medido que se deriva del rendimiento del sistema. Las métricas con frecuencia contienen información sobre indicadores como: cantidad de request, memoria libre, disponibilidad de los servicios, etc. Además, nos permiten definir gráficos, umbrales, y generar alertas cuando una situación se vuelve anómala.
Un trace es el registro documentado de una serie de eventos causalmente relacionados que suceden en una red. Los eventos no tienen que tener lugar dentro de una sola aplicación, pero sí deben ser parte del mismo flujo de solicitud. Un trace puede formatearse o presentarse como una lista de registros de eventos tomados de diferentes sistemas que participaron en el cumplimiento de la solicitud. En el mundo de los microservicios, se vuelve primordial entender cómo es el flujo de llamadas entre ellos ante el request que realizó el cliente.
¿Por qué usar Observabilidad?
Porque necesitamos:
-
Detectar y resolver problemas de manera temprana y proactiva para evitar riesgos a nivel de producción. Ante un quiebre del servicio, la terminal debe poder subsanar la falla lo antes posible.
-
Implementar cambios de forma segura a medida que se supervisa todo el entorno.
-
Proveer información para realizar ajustes en las aplicaciones, y así ofrecer un rendimiento y una experiencia de usuario mejorados.
-
Proveer información para optimizar la asignación de recursos.
¿Cómo se relacionan métricas, logs y trazabilidad?
Cada pilar tiene un objetivo preciso y funciona como un complemento para entender qué está pasando con nuestro sistema.
Las métricas nos dan un “pantallazo” sobre el estado general del sistema: son lo primero que hay que ver. Suelen organizarse en forma de dashboard y nos permiten visibilizar rápidamente las variables más importantes, como disponibilidad de los servicios, carga de los servidores, cantidad de usuarios activos, etc.
Pero estas mismas métricas pueden presentar comportamientos anómalos, y es acá donde entran los otros dos pilares: la trazabilidad y los logs. Son el “doble click” que hacemos para entender el problema de fondo. Los logs nos dan el detalle fino de un sistema, y las métricas nos permiten detectar problemas en el flujo de llamadas de un request específico.
En este contexto, es fundamental que existan atributos que nos permitan vincular los tres elementos: ir fácilmente de una métrica a los logs correspondientes y al request trazado. Estos atributos tienen que ser nombrados de la misma forma para poder realizar esta tarea.
¿Por dónde empezamos?
Elegir un stack
Es importante entender cómo es nuestra infraestructura para elegir la herramienta correcta. A fin de cuentas, la mayoría de las veces es una cuestión de costos.
Prometheus, Grafana: es “el” stack de la comunidad Open Source y Kubernetes. Es extremadamente sólido y ágil para el tratamiento de métricas, y es el producto más utilizado para dicho fin. Grafana forma parte de la instalación por defecto de Container Hub.
ELK o EFK: es el más versátil al momento de integrar los logs y explotarlos. Más allá de la versión gratis, el verdadero potencial se obtiene usando las versiones pagas.
Datadog: es un SaaS que resuelve, en una sola herramienta, los tres pilares de la observabilidad. Es muy fácil de integrar y evoluciona rápidamente en su funcionalidad. A veces en esta herramienta no encontramos el potencial que tenemos en Grafana o en Kibana.
Jaeger o Zipkin: son herramientas enfocadas en la trazabilidad. Las dos son open source, gratis y muy utilizadas en contextos de microservicios.
Definir alguna métrica de disponibilidad
Si queremos entender rápidamente lo que está pasando cuando nuestro sistema entra en una situación no deseada, sugiero definir métricas que nos hablen sobre la disponibilidad de nuestra aplicación. Y acá entra en juego lo funcional: a veces sólo contabilizar la cantidad de requests entrantes es una métrica que alcanza; pero lo ideal sería individualizar la disponibilidad de cada uno de los servicios que brindamos y compararlos con valores históricos.
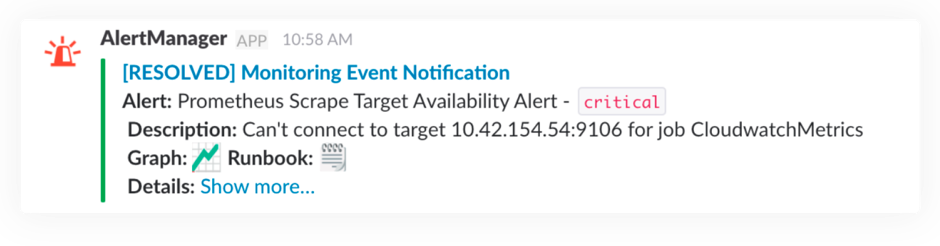
Generar alertas
Obviamente, no podemos estar todo el día mirando un dashboard para saber si las cosas andan bien o mal. Por eso definimos alertas sobre los valores anómalos de una métrica durante un periodo de tiempo. Es muy común, actualmente, enviar estas notificaciones por un medio como Slack, y que todo el equipo esté mirando este tipo de cosas; por supuesto, en pos de la cultura DevOps
Creo que es importante destacar el cambio cultural en cuanto a la manera en que se desarrolla software. El desarrollador debe ser consciente del ciclo de vida de lo que produce de punta a punta, y eso también incluye entender y saber cómo está corriendo su software.
Algunos dicen que dejamos de hablar de “monitorear” porque era una tarea de Ops totalmente aburrida; y que le pusieron el nombre de “Observabilidad” porque suena más “geek”.
Más allá de la humorada, creo que la Observabilidad o el Monitoreo (como lo quieran llamar) y su relación con el desarrollador es vital. Genera un flujo sobre qué cosas de las que hace funcionan bien y cuáles no (que se retroalimenta), de manera que el dev es el primero que puede dar cuenta de qué es lo que está pasando ante un problema. Lo empodera y lo hace participe todo el tiempo de lo que produce.
Las herramientas han evolucionado de tal manera que permiten a cada actor tener un desglose de la porción de software que le pertenece, así como la descentralización de la observabilidad para poder analizar al mismo tiempo diferentes aspectos. A fin de cuentas, tener un buen esquema de observabilidad y reaccionar lo antes posible ante situaciones no deseadas apunta directamente a la calidad de servicio que damos.
···
Atravesamos un tiempo en el que consumimos la información al instante. Si enviamos un mensaje por WhatsApp, esperamos que “no nos claven el visto” y nos den una respuesta significativa. Esa respuesta es relevante para nosotros como usuarios si podemos hacer o resolver nuestros problemas. Estamos en la época de lo inmediato, del todo momento y de la respuesta instantánea; del tiempo real y la información aumentada. En este escenario, nuestras aplicaciones son otra fuente de datos precisos y reales. Y los debemos aprovechar y poner en función de la experiencia de nuestros usuarios y clientes, para una respuesta inmediata y precisa en momentos críticos tales como un quiebre en el servicio de la terminal.